

Data science is poised to enhance DFIR
Seasoned investigators often find little information identifying initial breach conditions in complex environments. Sometimes, we can link this to experience, expertise, or pattern recognition we admire in the human mind.
Following a "hunch" has been an excellent tool for me in the 14+ years I have investigated breaches. It is not often that we have tools that do pattern recognition as quickly as humans during investigations, and we see automatic outputs even less frequently in data analysis.
Thankfully, based on some research by Google's founders and the excellent work done in Japan by their JPCERT, we have hope of a new way of looking at this problem in Windows Event Logs.
There is nothing worse than repeating a process ad nauseam to determine that something we are already confidently suspecting has taken place.
In many cases, an incident overview is returned from clients, and based on the zeitgeist that is the threat landscape, we may even know what happened before we can provide the proof.
Providing "proof" the old school way takes a significant amount of time and skill that comes with expensive resources, and it is often referred to as hard work when many business leaders have said: "Work smarter, not harder."
The Problem
We need to find the needle in a haystack to determine if something went wrong.
The rest of the problem
In a DFIR world, it is not our haystack, and the nuggets are either from a few minutes ago or a few days ago on networks that have existed in their current state for months or even years, and we may not know what data set we have or if this data is of high enough quality.
We are often in environments where the IP address ranges blur, the account naming conventions read like fictional character names, and the cyber hygiene practices suffer under the uptime and innovation requirements of the organization.
The Solution
Luckily this myriad of variances in data sets allowed the realization of some beneficial technologies that rely on the problem itself as detection.
We have mathematicians and expired patents to thank for a fun little adventure into finding evil.
Timing and the Markov Chain
A valuable thing to consider during an investigation is when something usually happens and when there is a deviation. But with limited data, it is hard to make a baseline determination, and we need to use another approach.
If you read Wikipedia on this, you will find it is "Sometimes characterized as "memorylessness" where we must constantly 'forget' which state the system is in." and use this to make predictions or determinations.
It sounds perfect for what we need because we rarely know what the network looks like at a given time, even if we all do not fully understand the math. After all, this is what manages your cruise control in your car, works out your flight plan, and is somehow involved in the stock exchange, and we know this is very unpredictable.
We need more than timing in the “Ranks.”
We need to find meaningful connections between entities, systems, and users and match this with strange timing. Here we have Larry Page to thank for an algorithm affectionately called "PageRank."
PageRank allows us to determine the number and quality of links between datapoints (or originally webpages) and rank them in order of relevance.
I often observe patterns in mile-long spreadsheets by scrolling my mouse wheel until it glows red, painstakingly analyzing the output of pivot tables, or creating complex searches in SIEM solutions that even MITRE can't answer. A large portion of the initial review process determines compromised accounts and endpoints and maps out lateral movement.
Determining the attackers' actions becomes easy with digital forensics tools once we know where they have been.
PageRank does this connection pattern recognition without lifting a finger.
Ideas getting married
The JPCERT put together an incredible tool called LogonTracer that leverages the above two concepts and more with almost pinpoint accuracy. It crucially brings speed and simplicity to a rather complex and tedious task.
Testing it in the real world
During investigations of a persistent threat in the last few months, I have become intimately familiar with a fairly extensive network. This familiarity with the network makes it easy to determine any goings-on by attackers that none of the usual security controls are capable of alerting on automatically, and some nursing is needed.
However, when I applied the simple process of deploying a Docker image to a woefully underpowered laptop and uploading the data I had worked hard at understanding, it spat out the same initial conclusions in a pretty little picture in a few minutes.
Graphing suspected malicious activity
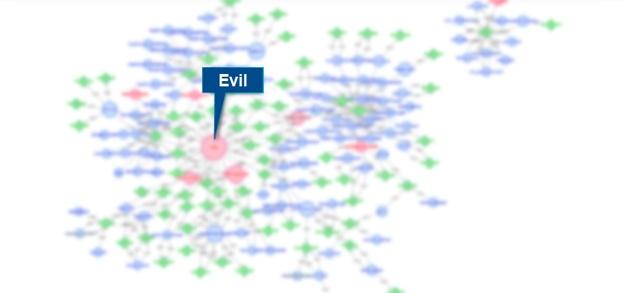
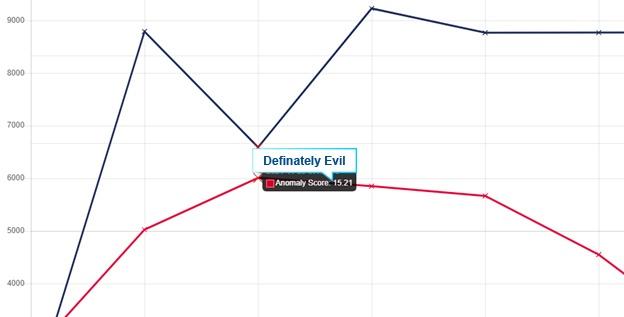
Upon further investigation
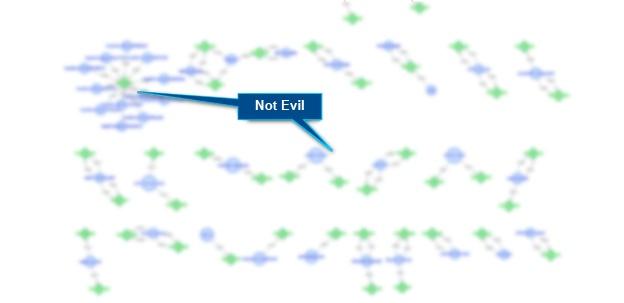
The verified normal activity
What if manual DFIR data analysis was not strictly needed?
We all know in the DFIR community that it is not the kit you use that makes you a good examiner, and this rings true when you place a seasoned investigator in front of a clunky tool, and they make it work better than you expected.
But what if we add a competent DFIR package to the above mix and add automation to the collection and parsing on more than just the event log data?
The possibilities are endless.
We could go
 Enter Velociraptor and “File Type Detection and Client-Server-Client Workflows”
Enter Velociraptor and “File Type Detection and Client-Server-Client Workflows”

Recently the DFIR community has offloaded a lot of the DFIR processing heavy lifting to endpoints, but not quite to robots just yet.
Even though this is not true for SOAR (Security Orchestration, Automation and Response) and other tools, it still hurts to think about automation in the DFIR space, even with UEBA (User and Entity Behavior Analytics) attempting to answer some security questions that forensic examiners shed light on daily.
In this super insightful contribution to the solution, the capabilities are starting to near an automated investigation.
Step 1: Locate interesting files based on file magics (using Yara, a tool aimed at - but not limited to - helping malware researchers to identify and classify malware samples).
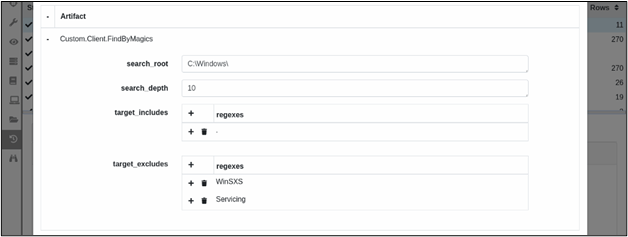
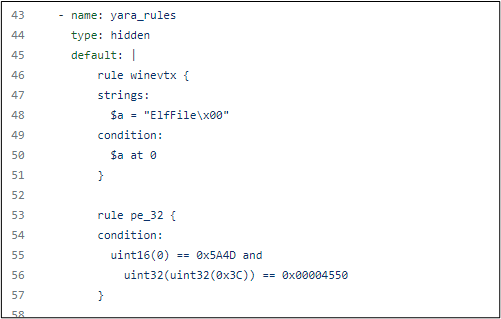
Step 2: Have the Velociraptor server decide what the client should do next.

Step 3: Send new orders to the client.
Some instructions may include uploading the file, parsing it for investigation-worthy data, submitting the results to a backend, and letting the magic happen.
Step 4: Send the results from all the identification processes to the algorithms we discussed above.
Step 5: Review only what is needed and speed up the TTR (Time to Resolution).
Conclusion
We are well on our way to the “Find Evidence” button.

As significant steps have been made in this direction already, I am excited about what the community is working on every day to speed up and simplify our lives as DFIR professionals.